引言:在数字世界中,寻找“通用健身房”
大家好,我是席志恒。今天,我想和大家聊聊一个激动人心的话题:如何教会人工智能(AI)像我们一样,在复杂的数字世界里独立思考、探索并完成任务。想象一下,一个AI助手不仅能回答你的问题,还能帮你预订机票、在论坛里找到关键信息,甚至在虚拟世界里完成科学实验。这就是我们所说的“智能代理”(Agent)的终极形态。
然而,通往这条路的探索并非一帆风顺。就像人类需要通过与环境的互动来学习成长,AI智能体也需要一个“训练场”来磨练技艺。过去,很多研究依赖于让AI模仿人类专家的操作记录,这就像是让一个学生只通过背诵标准答案来学习,虽然能应付一些考试,但一旦遇到新问题就束手无策。它缺乏真正的理解和适应能力。
我们意识到,真正的学习源于“试错”与“探索”。这正是强化学习(Reinforcement Learning, RL)的核心思想。但是,当时的AI社区缺少一个统一、强大、且贴近现实世界的“健身房”,能让不同类型的智能体在多样化的环境中,通过强化学习从零开始进化。这就是我们创造 AgentGym-RL 的初衷:为AI智能体打造一个 универсальный、可扩展的交互式强化学习框架。
论文摘要 (Nature 风格)
自主智能体(Autonomous agents)能在复杂现实世界任务中执行序贯决策,是人工智能领域的前沿。这些智能体应通过与环境的探索性交互来获取知识与技能,模拟人类认知发展。然而,当前领域内缺乏一个统一的、交互式的强化学习(RL)框架,能有效支持智能体在多样化现实环境中从零开始训练,而无需依赖监督式微调(SFT)。为填补此空白,我们引入了 AgentGym-RL,一个专为多轮交互决策任务设计的LLM智能体训练框架。其模块化、解耦的架构保证了高度的灵活性与可扩展性,并集成了多种真实世界场景及主流RL算法。此外,我们提出 ScalingInter-RL 训练策略,通过在训练初期限制交互轮数以侧重"利用",随后逐步增加交互视界以鼓励"探索",实现了探索-利用的平衡与RL优化的稳定性。实验证明,该框架与方法能显著提升智能体性能,使我们的7B模型在27个任务上的表现媲美甚至超越了顶尖商业模型。我们将开源AgentGym-RL的完整代码与数据集,赋能社区共同发展下一代智能代理。
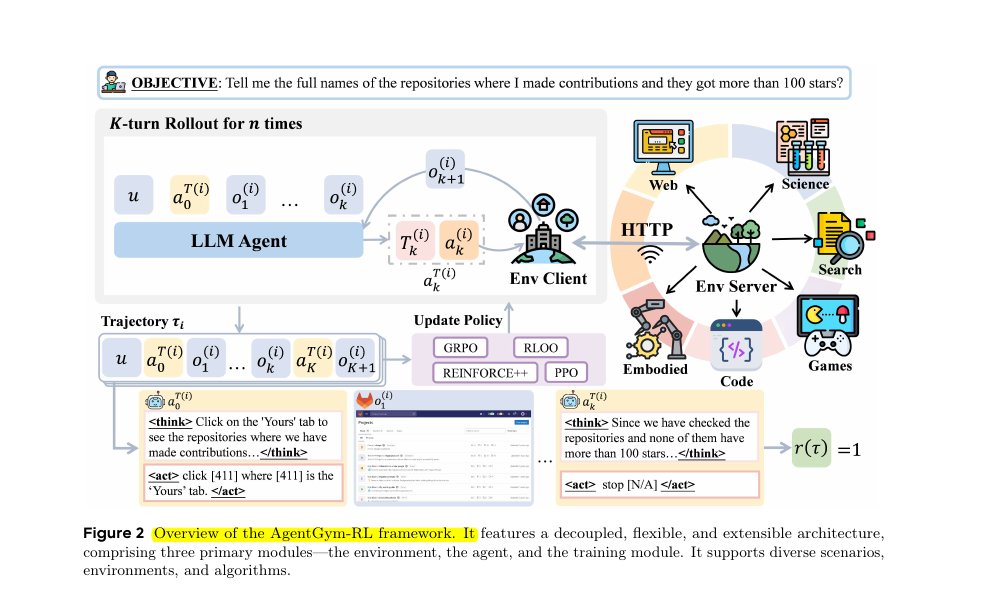
图1:AgentGym-RL 核心架构
展示了AgentGym-RL框架的核心组件和交互流程,体现了模块化设计的优势。
AgentGym-RL:为智能体打造的模块化宇宙
那么,AgentGym-RL 究竟是什么样子的?你可以把它想象成一个高度模块化的乐高世界。它主要由三个核心组件构成,每个组件都可以独立插拔和替换,这为研究和开发提供了极大的便利。
- 环境 (Environment) 模块:这是智能体的“训练场”。我们没有局限于单一场景,而是构建了一个包罗万象的环境集合,涵盖了网页浏览(WebArena)、深度信息检索(Deep Search)、文字游戏(TextCraft)、模拟物理任务(BabyAI)以及科学探索(SciWorld)等。每个环境都像一个独立的星球,有着独特的规则和挑战。
- 智能体 (Agent) 模块:这是我们的“运动员”。它封装了大型语言模型(LLM)的核心,负责接收环境信息、进行思考,并作出决策。这个模块的设计支持长时规划、自我反思等高级认知能力。
- 训练 (Training) 模块:这是“教练团队”。它实现了多种主流的强化学习算法,如 PPO、GRPO 等。教练们根据智能体在训练场上的表现(即获得的奖励),来调整和优化它的决策策略。
这三者通过统一的协议进行通信,形成了一个“产生数据 -> 学习策略 -> 产生更好数据”的闭环。这种解耦的设计,意味着你可以轻易地为这个宇宙添加新的星球(环境),或者为运动员换上新的大脑(智能体模型),甚至是聘请新的教练(训练算法),而无需改动整个系统。
静态图1:AgentGym-RL 架构概览
类比一个健身房:环境是各式各样的健身器材,智能体是来训练的运动员,而训练模块则是负责指导和提升运动员表现的教练团队。三者解耦,灵活组合。
交互动画1:强化学习的核心循环
这是一个简化的强化学习过程。智能体(蓝色小球)根据当前策略选择一个行动,环境(右侧)接收行动后,返回新的状态和奖励。这个反馈被用来优化智能体的策略,使其在未来能做出更好的决策。
累计奖励: 0 | 状态: 待开始
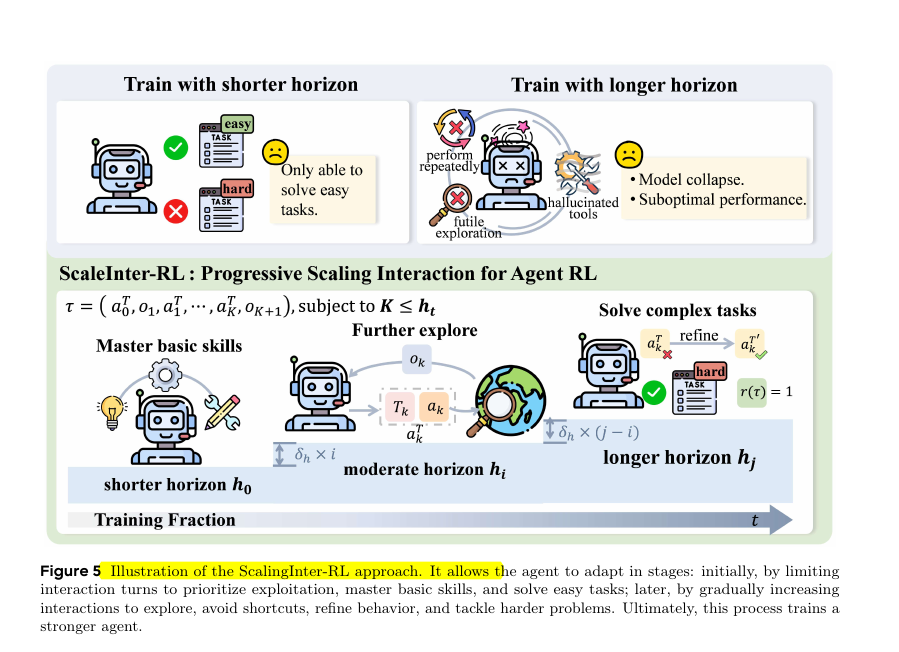
ScalingInter-RL:从浅水区到深海的智慧进化
有了顶级的健身房,我们还需要一套科学的训练方法。直接把一个新手扔进最复杂的任务中,很可能会让他感到挫败,甚至形成错误的习惯,我们称之为“训练崩溃”。这在强化学习中是一个常见难题:如何在“探索”新可能性和“利用”已知有效策略之间找到最佳平衡点?
为此,我们提出了 ScalingInter-RL 策略。这个名字听起来很技术,但它的核心思想非常符合直觉。我们可以用学游泳来类比:
- 第一阶段(短视界探索):训练初期,我们把智能体放在“浅水区”。这意味着我们限制它与环境的交互轮数。在这个阶段,任务相对简单,智能体可以快速学会一些基本技能(比如在网页上点击正确的按钮),并获得持续的正反馈。这建立了它的信心和基础能力,也就是“利用”现有知识。
- 第二阶段(渐进式扩展):当智能体在浅水区游刃有余后,我们逐渐把水位调高,也就是逐步增加最大交互轮数。这鼓励它去“深水区”探索,尝试更长、更复杂的行动序列来解决难题。比如,它可能会发现,有时候需要先搜索,再导航,再点击,这样一个多步骤的计划才能完成任务。
这种“渐进式交互扩展”的策略,就像一位好老师,因材施教,循序渐进。它既避免了初期因过度探索导致的混乱,又保证了后期能学会高级、复杂的策略,从而实现了稳定而高效的训练。智能体在这个过程中,学会了规划、反思,甚至是“走弯路再回头”的智慧。
交互动画2:ScalingInter-RL 学习策略
体验三种不同的学习模式。观察“固定短视界”如何限制成长,“固定长视界”如何导致失败,而“ScalingInter-RL”如何通过循序渐进实现最佳学习效果。
智能体得分: 0 | 状态: 待开始 | 最大交互轮数: 3
交互动画3:探索 (Exploration) vs. 利用 (Exploitation)
智能体需要在已知最佳路径(利用)和寻找可能更好的新路径(探索)之间做出权衡。这个动画展示了纯粹利用、纯粹探索以及二者平衡后的效果。粒子代表智能体,目标是到达右上角的星星区域。
找到目标粒子数: 0
惊人成果:7B模型挑战巨头的底气
理论和框架的优美固然重要,但最终还是要用实验结果说话。我们在五个不同的真实世界场景中,对使用 AgentGym-RL 和 ScalingInter-RL 训练出的模型进行了广泛测试。结果是令人振奋的。
我们的 7B(70亿参数)模型,在经过我们的框架训练后,其平均成功率不仅远超同等规模的其他开源模型,甚至在多个任务上媲美乃至超越了像 GPT-4o、Gemini-2.5-Pro 这样的千亿参数级别的商业闭源模型!这是一个典型的“以小博大”的成功案例。
这说明了什么?它揭示了一个深刻的洞见:对于智能体的进化而言,单纯堆砌模型参数的“体型”,远不如通过高质量的交互训练来提升“智慧”更有效。 我们的工作证明,一个中等规模的模型,只要给予正确的训练环境和科学的训练方法,完全有能力爆发出惊人的决策智能。这为开源社区发展自己的高性能智能体,指明了一条切实可行的道路。
静态图2:性能对比:以小博大
此图根据论文图1简化而来,直观展示了我们的7B模型(Ours-7B)在多个任务上的平均成功率,超越了许多参数量远大于它的模型。
更有趣的是,我们发现,在测试时给予智能体更多的"思考时间"——也就是允许更多的交互轮数——其性能也会显著提升。这再次印证了我们的核心观点:交互,是解锁智能的关键钥匙。
图2:实验结果深度分析
展示了在不同任务类型和训练策略下的详细性能表现,验证了ScalingInter-RL方法的有效性。
交互动画4:智能体学到的优雅决策流
生活化类比:想象无数微小的尘埃,在空中随一阵看不见却又和谐有序的风飘动,形成了优雅的涡流和线条。这正如此动画所示,代表了我们训练好的智能体在面对复杂问题时,所形成的内在、高效且有序的决策“流场”。
反思与展望:前路漫漫,但星光璀璨
尽管我们取得了令人鼓舞的成果,但坦诚地说,这只是万里长征的第一步。我们的智能体在某些方面仍然存在局限性。
例如,在一些需要极其精细操作的网页任务中,智能体有时会陷入“过度交互”的怪圈——反复点击、不必要地滚动页面,虽然最终可能也找到了正确位置,但过程效率低下。在复杂的科学推理任务,特别是化学混合实验中,所有模型(包括我们的)都表现不佳,这揭示了当前LLM在理解和模拟复杂物理化学过程方面的系统性短板。
静态图3:失败案例分析:过度交互
此图描绘了一个典型的失败模式。智能体(机器人图标)虽然到达了正确的页面,但陷入了对一个无效按钮(灰色按钮)的重复点击循环中,浪费了大量的交互步骤,未能高效完成任务。
这些挑战也为我们指明了未来的方向:
- 提升泛化能力:如何让智能体将在一个环境中学的技能,迁移到全新的、未曾见过的环境中去?
- 更真实、更长期的任务:未来的挑战将是更长时间维度、与物理世界更紧密结合的任务,这对智能体的感知、推理和执行能力都提出了更高的要求。
- 多智能体协作:从单个智能体的“独奏”,到多个智能体协同合作的“交响乐”,这将是智能体研究的下一个华丽篇章。
AgentGym-RL 只是一个开始。我们希望通过开源这个框架,能够吸引更多研究者加入,共同为这个激动人心的领域添砖加瓦。我相信,在不远的未来,真正可靠、通用、智能的AI代理,将深刻地改变我们的生活和工作方式。
交互动画5:测试时算力扩展
在测试阶段,给予智能体更多的交互机会(相当于更多的“思考时间”),通常能带来更好的性能。拖动滑块,增加交互轮数,观察智能体(蓝点)能否成功穿越更复杂的迷宫(由噪声生成)。
状态: 待命