引言:AI需要一次“大脑”级别的革命
大家好,我是James。在人工智能的星辰大海中,我们建造了一艘又一艘名为“大型语言模型”(LLMs)的巨舰。它们拥有强大的智能,能够写作、绘画、编程,几乎无所不能。然而,这些巨舰的引擎却异常“饥渴”——它们消耗着惊人的计算资源和能源,仿佛一座座永不停歇的数字火山。每当我们惊叹于它们的智慧时,背后都是数据中心巨大的风扇在轰鸣。
这让我不禁思考:我们真正的智慧源泉——人类大脑,是如何做到在极低的功耗下(大约20瓦,仅相当于一个昏暗的灯泡)实现如此复杂和高效的思考的?答案隐藏在一个核心原则中:稀疏性 (Sparsity)。大脑在处理信息时,并不会“全力以赴”,而是像一位技艺高超的指挥家,在恰当的时刻,只激活乐团中必需的那些乐手。大部分神经元在绝大多数时间里都保持着优雅的沉默。
这个深刻的洞见,正是我们“SpikingBrain”项目的起点。我们希望跳出当前AI模型“暴力计算”的框架,转而向我们的大脑学习,构建一种全新的、基于脉冲(Spike)和稀疏性的大模型架构。我们的目标不仅仅是让AI更聪明,更是要让它变得更“智慧”——以一种更高效、更优雅、更接近生命本质的方式去思考和创造。这不仅是一次技术的迭代,更是一场对AI能效与可持续未来的深刻探索。
摘要 (Abstract)
当前的大型语言模型(LLMs)虽然在性能上取得了显著突破,但其巨大的计算和能源开销限制了其广泛应用与可持续发展。受人脑信息处理中固有的多尺度稀疏性启发,我们提出了SpikingBrain,一个融合了脉冲神经网络(SNNs)机制的大模型框架。该框架通过引入事件驱动计算、自适应稀疏性和模块化功能特化等脑启发机制,构建了一种混合高效的注意力模型架构。其核心在于将传统的密集浮点数计算转化为稀疏的脉冲信号处理,并结合专家混合(MoE)模块,实现了在模型运行时仅激活少量神经元和参数。我们提出了一套通用的模型开发管线,支持从现有的开源Transformer模型进行低成本转换训练,以及从零开始进行高效预训练。实验结果表明,SpikingBrain能够在仅使用不到2%原始数据进行转换训练的情况下,达到与主流开源模型相当的性能。在处理4M长度的序列时,其首次Token生成时间(TTFT)加速超过100倍,同时在推理过程中实现了超过69%的脉冲稀疏度。这些结果不仅为主流AI模型提供了显著的能效提升方案,也为设计下一代神经形态计算芯片的微架构提供了宝贵的量化依据,预示着构建高效、通用且可扩展的人工智能系统的新路径。
第一章:灵感之源——大脑的“节能”艺术
要理解SpikingBrain,我们首先要潜入大脑的微观世界。想象一下,你正在参加一个盛大的派对。在传统的AI模型(比如Transformer)里,这个派对就像一场狂欢,每个人都在同时大声说话,试图让所有人听到自己的声音。信息是密集的、并行的,虽然热闹,但也混乱且极其耗能。
而我们的大脑,则是另一种派对。它更像一个高效的“信息接力沙龙”。只有当一个人(神经元)收到了足够重要的信息(输入信号累积到阈值),他才会“举手发言”(发放一个脉冲),并将这个简洁的信息传递给特定的几个人。这就是事件驱动 (Event-driven) 的本质。不是所有神经元都在不停地计算和广播,只有“有话要说”的神经元才会被激活。
动画1:激活模式的交响乐 - 密集 VS 稀疏
类比:左边是传统AI,所有乐器(神经元)都在不停地演奏。右边是SpikingBrain,如同优秀的指挥家,只在需要时唤醒特定的乐器,创造出和谐且高效的乐章。点击右侧画布,看看输入信号如何只激活一小部分神经元。
当前模式: 密集激活
能耗指示: 高
这种“按需发言”的策略,自然而然地带来了多尺度稀疏性 (Multi-scale Sparsity)。它体现在多个层面:
- 时间稀疏性:在任何一个瞬间,只有极少数神经元是活跃的。
- 空间稀疏性:一个神经元的连接也不是遍布全网,它只与特定的神经元社群进行交流。
- 模块稀疏性:当处理特定任务,比如识别一只猫时,大脑只会激活视觉皮层和相关记忆区域的特定模块,而语言中枢则会保持静默。
此外,大脑的记忆也并非是像素级的录像,而是高度压缩和抽象的。我们通过压缩记忆 (Compressed Memory) 和树突动力学 (Dendritic Dynamics) 等机制,模拟了神经元之间复杂的、非线性的信息整合过程。这就像神经元不仅能做简单的加法,还能执行复杂的"如果...那么..."逻辑判断,使得单个神经元的功能远比传统AI中的计算单元强大。
图1.1:大脑稀疏性机制的深度解析
这张图展示了大脑中多尺度稀疏性的具体表现,从单个神经元的脉冲发放模式到整个神经网络的功能模块化激活,为SpikingBrain的设计提供了重要的生物学依据。
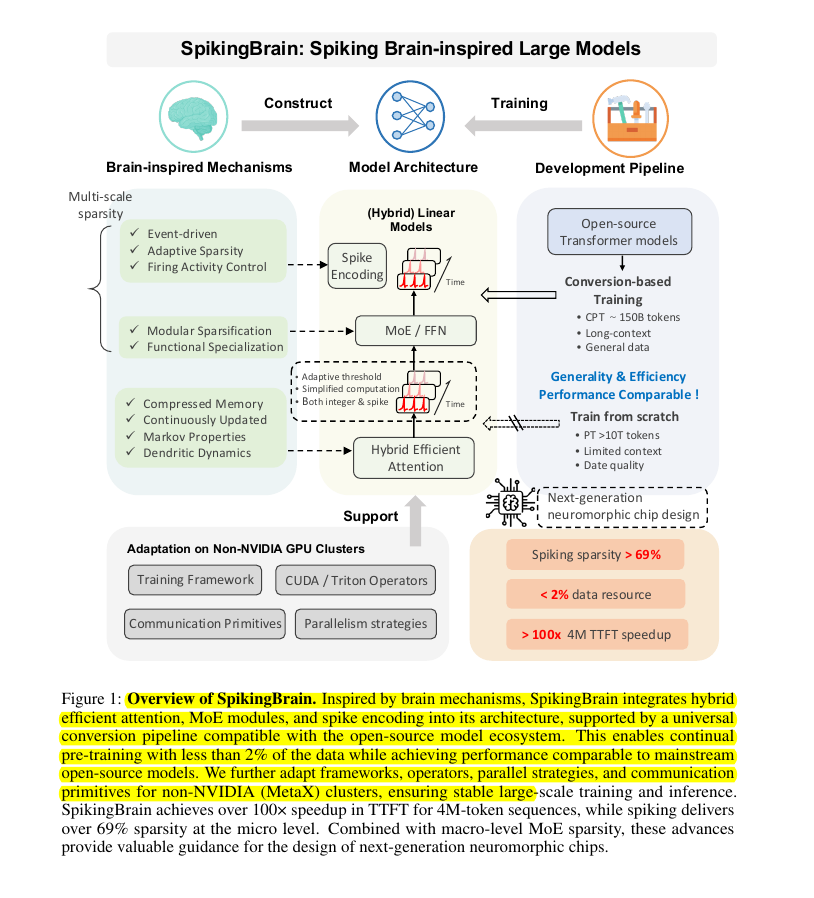
第二章:设计蓝图——构建混合动力的高效引擎
有了大脑的节能蓝图,我们如何将其转化为计算机代码和模型架构呢?我们没有完全抛弃现有Transformer模型的强大结构,而是巧妙地进行了一场“混合动力”改造。
从密集数值到稀疏脉冲:信息的全新编码
传统AI处理的是连续的浮点数值,比如一个像素的亮度可能是0.85。而在SpikingBrain中,信息被编码成一系列离散的脉冲 (Spikes)。这就像用摩斯电码来传递信息,虽然只是“点”和“划”,但通过时间和频率的变化,可以表达任何复杂的内容。这种编码方式是稀疏计算的基础。
动画2:信息编码的变革 - 模拟信号 vs 脉冲信号
类比:左侧平滑的波形代表传统AI中的连续数值。右侧,我们将这个波形的高度转换成了脉冲的频率。波峰越高,脉冲越密集。这是将世界“翻译”成大脑语言的第一步。
专家混合(MoE):只唤醒需要的专家
为了实现模块化稀疏,我们引入了专家混合 (Mixture of Experts, MoE) 架构。想象一下,一个大型公司里,你有一个问题。你不会把问题发给全公司的所有人,而是会通过一个“路由器”(总机),找到最擅长解决这个问题的那个“专家部门”。
在SpikingBrain中,模型被分成了许多个“专家”网络。当一个任务(例如,一段文本)输入时,一个轻量级的门控网络会判断这个任务应该由哪些专家来处理。于是,只有被选中的少数专家会被激活和计算,模型的其他大部分都处于“休眠”状态,极大地节省了计算资源。
动画3:专家咨询室 - 任务的智能路由
类比:不同颜色的“任务”信息包被发送到一个中央路由器,路由器会根据颜色(任务类型)将其精确地发送给对应的“专家”模块进行处理,其他专家则保持待机。
最新任务导向: 无
混合高效注意力机制
我们对Transformer模型的核心——注意力机制(Attention)——进行了深度改造,创造了混合高效注意力 (Hybrid Efficient Attention)。它能够在脉冲的世界里高效地计算信息的重要性,确保模型在稀疏激活的状态下,依然能准确捕捉到关键信息。这就像在之前那个安静的“信息接力沙龙”里,每个人都能精准地判断出哪些信息是“噪音”,哪些是值得传递下去的“金玉良言”。
图1:SpikingBrain 整体架构
这张图概括了我们的设计哲学:融合脑启发机制(左侧)、创新的混合模型架构(中部)以及灵活的开发流程(右侧),最终实现超高的稀疏度和性能加速。
第三章:训练之道——两条路径,通往高效智能
一个优秀的架构也需要高效的训练方法。为此,我们设计了灵活的开发管线,提供了两条截然不同的路径来“孕育”我们的SpikingBrain。
- 转换式训练 (Conversion-based Training): 这是我们的“捷径”。我们可以拿一个已经在海量数据上训练好的、成熟的开源Transformer模型,然后通过一个精巧的“翻译”过程,将其权重和结构转换为SpikingBrain的形态。这个过程就像是把一本经典小说改编成电影,保留了核心故事,但用全新的、更高效的视觉语言来呈现。惊人的是,这个“改编”过程非常高效,我们发现仅需使用不到2%的原始预训练数据,就能让转换后的模型恢复到接近原始模型的性能!
- 从零训练 (Train from Scratch): 这是更具挑战性也更具潜力的“原生”路径。我们直接在脉冲神经网络的框架下,从一个随机初始化的模型开始,用大量数据进行训练。这个过程虽然需要更多的计算资源和高质量的数据,但它能让模型“土生土长”地学习如何在稀疏的世界里思考,有可能达到更高的性能和效率上限。
图2:训练路径选择 - 转换 vs 从零开始
我们可以选择快速的转换路径,利用现有生态;也可以选择从零开始,追求极致的原生性能。
这种双路径策略赋予了SpikingBrain极大的灵活性,使得我们既能快速利用和融入现有的AI生态,又能不受束缚地探索脉冲神经网络的原生潜力。
第四章:惊人成果——当速度与节能相遇
理论和架构的优雅,最终需要通过实际效果来检验。SpikingBrain的表现没有让我们失望,甚至远超预期。我们在多个维度上看到了数量级的提升:
- > 69% 的脉冲稀疏度:这意味着在模型运行时,超过三分之二的时间里,绝大多数神经元都处于“节能”的静默状态。这直接印证了我们脑启发设计的成功。
- > 100x 的TTFT加速:在处理长达400万个Token的超长序列任务时,SpikingBrain生成第一个Token的时间(Time To First Token)比同类模型快了100倍以上。对于需要快速响应的交互式应用,这是革命性的提升。
动画4:能效竞赛 - 传统AI vs SpikingBrain
类比:两部手机运行同样复杂的任务。左边的代表传统大模型,电量飞速下降。右边的SpikingBrain,凭借其稀疏计算,能以极低的能耗完成更多工作。
这些成果的意义是深远的。它不仅仅是数字上的胜利,更代表了一种全新的可能性:我们可以在个人电脑、智能手机甚至更小的边缘设备上,运行今天只有在云端数据中心才能承载的强大AI模型。这为AI的普及化和民主化打开了一扇新的大门。同时,我们的研究也为下一代神经形态芯片的设计提供了具体的、可量化的指导。这些芯片从硬件层面就模拟了大脑的结构,与SpikingBrain这样的软件框架是天作之合,它们的结合将有望引领一场真正的计算革命。
动画5:未来之流 - 信息的优雅舞蹈
这个动画没有直接的物理类比,它更像是一种艺术化的表达。想象这些流动的光点是SpikingBrain中高效传递的信息脉冲。它们在复杂的向量场中穿梭,形成有序而动态的结构,既不混乱,也不冗余,完美展现了稀疏计算的内在美感和强大生命力。
结语:迈向可持续的通用人工智能
SpikingBrain的旅程,是一次从生命智慧到人工智能的回归与超越。我们从大脑数十亿年进化出的高效机制中汲取灵感,并将其与现代深度学习的强大框架相结合,证明了性能与效率并非不可兼得。我们相信,未来的通用人工智能(AGI)不应建立在无尽的能源消耗之上,而应像生命本身一样,以一种可持续、可扩展且优雅的方式存在。
这仅仅是一个开始。我们正在探索更复杂的脑启发机制,优化我们的训练算法,并与硬件伙伴合作,推动神经形态计算的边界。我们希望SpikingBrain能够激发更多研究者共同思考:如何构建一个不仅聪明,而且“智慧”的AI未来。感谢大家的关注。